Rimac: la supercar con GNU/Linux
Chi è appassionato di automobili conosce già Rimac, ma per il resto del pubblico il nome potrebbe risultare nuovo. In effetti si tratta di una azienda decisamente moderna, fondata nel 2009 in Croazia. Rimac ha rilasciato nel 2019 il suo secondo grande progetto la Rimac C_Two: si tratta di una automobile elettrica capace di raggiungere la velocità di 415km/h, con una accelerazione da 0 a 100 km/h in appena 1,97 secondi. Per fare un confronto, la Bugatti Veyron (a combustione) arriva a 407 km/h, con una accelerazione da 0 a 100 in 2,5 secondi. Mentre la Tesla Model S, l’auto elettrica più famosa ma non progettata per le corse, arriva al massimo a 250km/h, anche se può accelerare da 0 a 100 in 2,6 secondi (quindi paragonabile alla Veyron). Ma non solo: il vero punto di forza della Rimac non è la grande velocità, ma l’alto livello di automazione. Presentata nell’estate del 2019, e in consegna ai clienti che l’hanno prenotata nei primi mesi del 2020, è la prima auto a guida autonoma di livello 4.
Per capire di cosa si tratti, ricordiamo che questo è lo standard dei sei differenti livelli di guida autonoma delle automobili:
• Livello 0: Sono presenti sistemi automatici che intervengono in casi specifici (es: ABS in caso di frenata), ma nessun computer gestisce la guida per lunghi periodi di tempo
• Livello 1 (hands on): I sistemi di guida automatica possono controllare l’andamento della macchina, ma solo se anche il guidatore la gestisce. Esempio: cruise control o parcheggio assistito.
• Livello 2 (hands off): I computer sono in grado di guidare la macchina, ma solo per brevi periodi di tempo, quindi una persona deve sempre avere le mani sullo sterzo. Se si tolgono le mani dal volante per più di qualche minuto, la guida autonoma deve essere interrotta.
• Livello 3 (eyes off): La macchina può guidare da sola in quasi ogni situazione, senza che il guidatore presti attenzione alla strada. Però la macchina può richiedere all’uomo, in situazioni complicate, di riprendere il controllo manuale.
• Livello 4 (mind off): Non c’è alcun bisogno dell’intervento umano per garantire la sicurezza del viaggio: l’uomo può anche dormire durante il viaggio. In caso di problemi, la macchina riesce a parcheggiarsi da sola in luoghi dedicati al soccorso (es: piazzole o corsia di emergenza).
• Livello 5: Non è mai richiesto alcun intervento dell’uomo, e non è previsto che una persona guidi l’auto. Per esempio, un servizio di taxi senza autista in cui la macchina raccoglie e trasporta i clienti senza che vi sia un pilota, oppure un veicolo per il trasporto di merci senza impiego di personale.
Per capirci, le macchine come la Tesla Model S al momento si trovano al livello 3. Raggiungendo il livello 4, la Rimac C Two è effettivamente la prima auto in grado di guidare da sola a essere consegnata nelle mani di clienti (150 persone hanno pagato i quasi 1,8 milioni di euro richiesti per questa hypercar in tre settimane dall’annuncio dell’apertura delle prenotazioni).
Ci si potrebbe chiedere: che importanza ha la Rimac C_Two per il mercato globale? A un prezzo che sfiora i due milioni di euro di sicuro nessun cliente comune se la può permettere. Ma la realtà è che la Rimac potrebbe cambiare il mercato automobilistico molto più della Tesla. Se Tesla infatti punta proprio a vendere veicoli, Rimac punta a vendere tecnologia. Le tecnologie che Rimac ha implementato nella sua lussuosa automobile a tiratura limitata verranno infatti presto cedute in licenza a altri produttori di automobili, diffondendole. Non avendo accordi di esclusiva con altri produttori, questo permetterà l’abbassamento dei prezzi dei vari sistemi di guida autonoma, perché Fiat, Mercedes, Peugeot, Toyota, e altri marchi potranno integrare le soluzioni inventate da Rimac senza dover spendere un capitale enorme per reinventare la ruota.
Ne abbiamo parlato con Tomislav Lugarić, ICU Software Manager di Rimac Automobili. Le tecnologie di Rimac sono infatti basate sull’open source: i computer di bordo utilizzano una distro Linux embedded e le librerie Qt.

Linux Magazine – Schermi e computer sono presenti nelle automobili da decenni, ma fino a pochi anni fa venivano usati più che altro per sistemi di intrattenimento. Oggi, invece, sono sempre più usati per visualizzare statistiche e permettere all’utente di modificare parametri relativi al motore, la distribuzione della coppia, lo stile di guida. Cosa si può fare con gli schermi presenti nella Rimac C Two?
Tomislav Lugarić – In effetti, la transizione dalle classiche manopole analogiche, interruttori, e rotelle verso il mondo digitale ha ridefinito completamente il modo in cui interagiamo con le automobili.
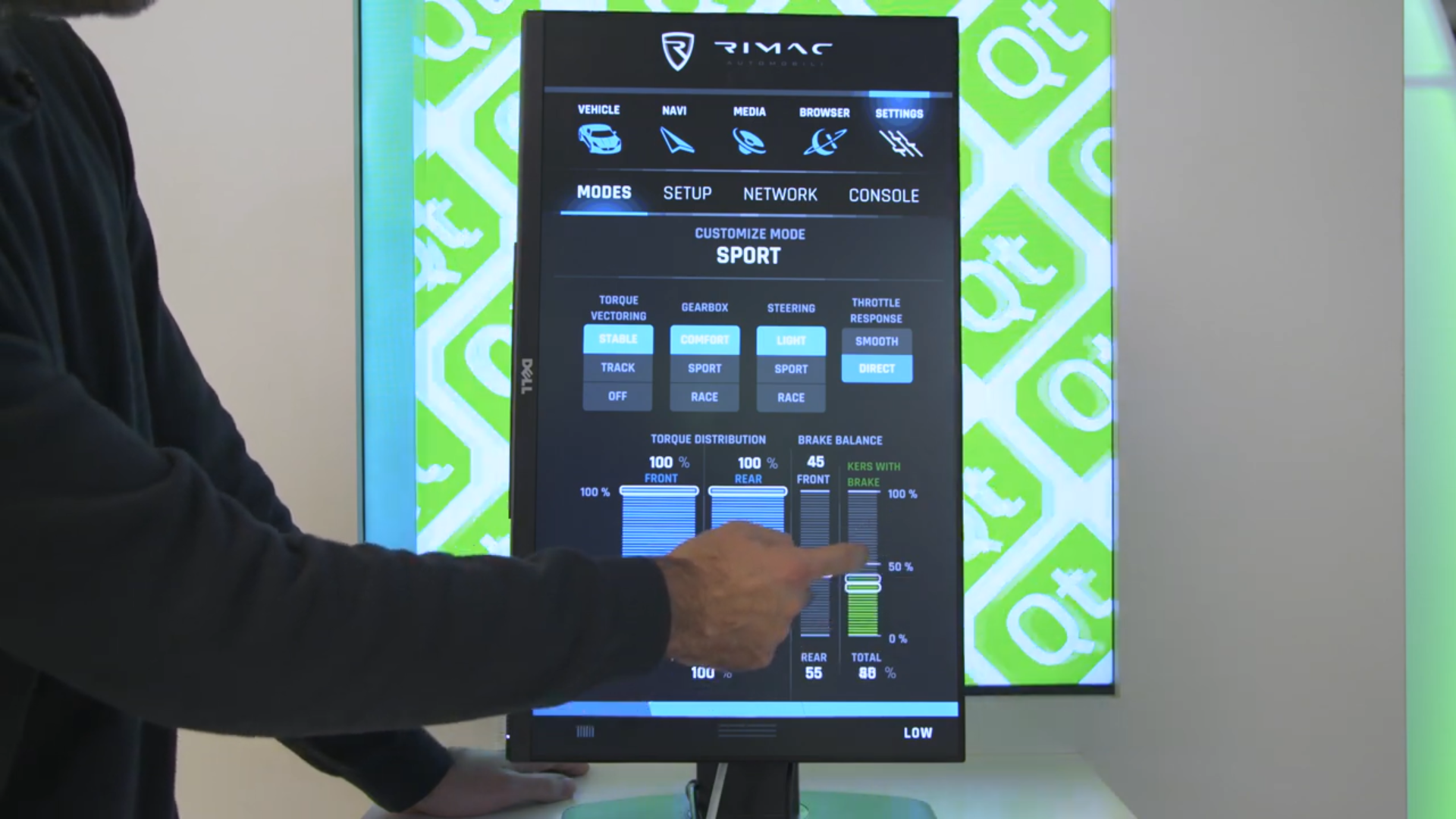
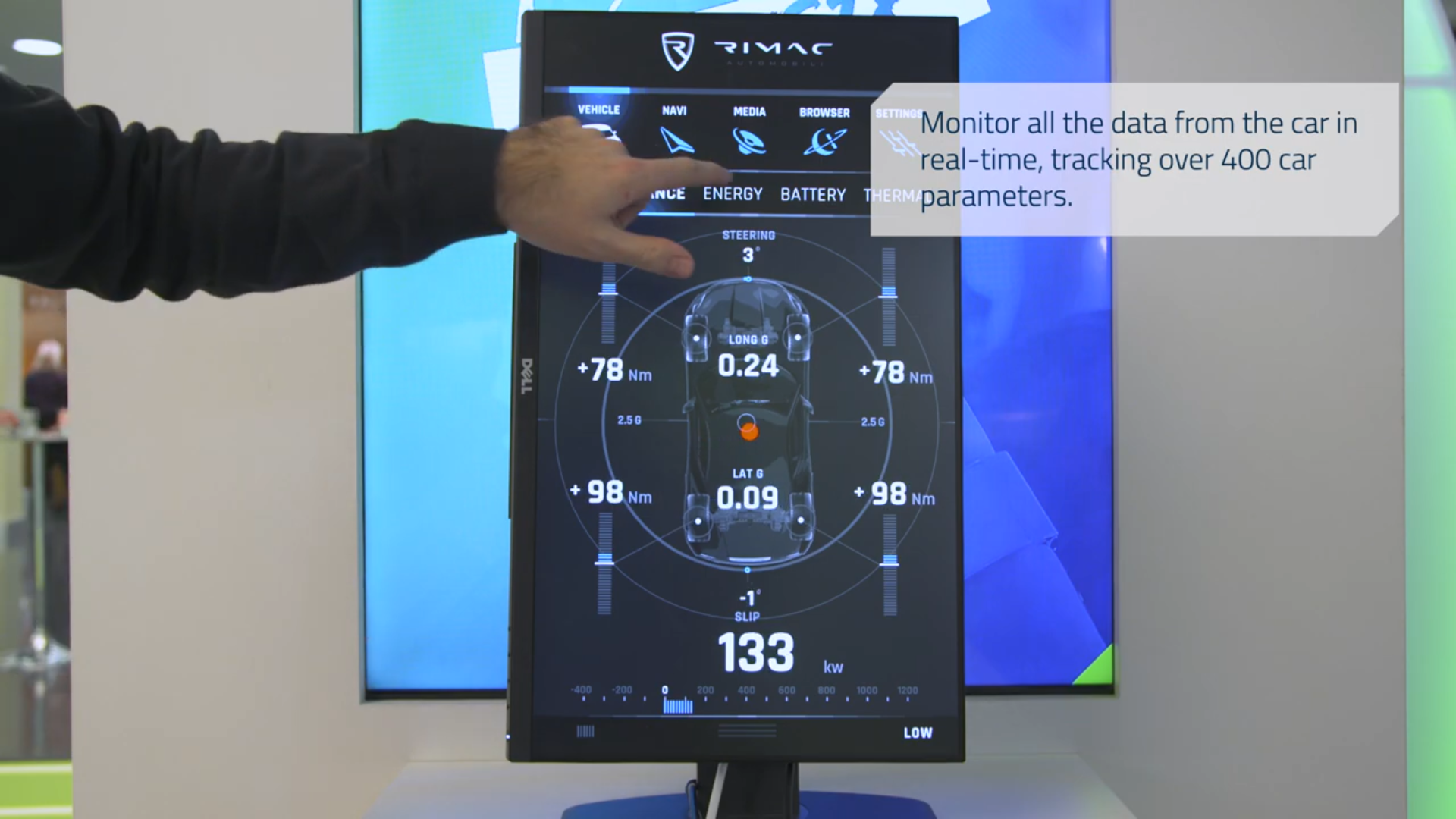
Nell’hypercar Rimac C Two il nostro obiettivo era di trovare il compromesso perfetto tra le classiche interazioni tattili e meccaniche, e i vantaggi che gli schermi digitali ci offrono. Ci sono ben 6 schermi all’interno della macchina. Il cruscotto digitale, davanti al guidatore, è dedicato a fornire solo i dati relativi alla guida. Questo display ha diverse configurazioni, che cambiano a seconda dell’attuale modalità dell’auto. Per esempio, quando si è in modalità di navigazione la maggioranza dello spazio sullo schermo è dedicato a una mappa 3D, con cose come la velocità e altri indicatori posizionati ai lati. In modalità sportiva cose come la velocità, la coppia, l’accelerazione e i tempi del giro di pista vengono presentate al pilota. C’è un certo numero di widget aggiuntivi, che il guidatore può attivare a seconda della modalità di guida usando dei pulsanti sul volante. Una parte di queste informazioni viene mostrata sullo schermo del passeggero, proprio sopra il vano portaoggetti, così anche il copilota può vedere le informazioni più importanti. I parametri più importanti della trazione sono configurati tramite tre rotelle su schermo. Queste rotelle hanno uno o più anelli come fonte di input, e al centro possono visualizzare un output. Uno di questi display viene anche usato come pulsante. Queste manopole digitali possono essere usate per attivare il motore, cambiare marcia, modificare la distribuzione della coppia tra gli assi, selezionare la modalità di guida e il controllo di trazione. Le rotelle sono posizionate vicino lo sterzo, per permettere al guidatore di impostare il comportamento dell’automobile e visualizzare l’attuale configurazione con una sola occhiata. Infine, lo schermo centrale è quello in cui si trova la maggioranza delle funzioni interattive. Qui il guidatore e il passeggero possono accedere a tutte le funzioni standard dell’auto, come il climatizzatore, la regolazione dei sedili, le luci, le funzioni multimediali (riproduzione da USB, streaming, e radio), il bluetooth con lo smartphone, Android Auto, Apple CarPlay, e un navigatore intelligente sempre connesso a internet. Abbiamo in programma anche di integrare il supporto per l’analisi dei dati raccolti dall’auto, come foto e video dalla videocamere oppure statistiche sulla guida. Dal momento che l’auto è connessa a internet, abbiamo pianificato il rilascio di nuove funzioni anche dopo la vendita.
LM- Per quali applicazioni usate le librerie libere Qt, e perché le avete preferite alle alternative?
TL- Le Qt hanno dimostrato diversi punti di forza negli anni. Anche se sono più che altro conosciute come uno strumento per creare interfacce grafiche, offrono un modo semplice e cross-platform per fare molto di più. Al di là della progettazione delle interfacce grafiche, abbiamo usato le Qt anche per cose come le interfacce di rete, la memorizzazione dei dati, la transcodifica e l’interazione con il CAN bus dell’auto. Occupandosi di un sacco di cose a basso livello per noi, le Qt ci hanno permesso di concentrarci sul nostro problema piuttosto che costringerci a creare uno strumento di sviluppo tutto nostro.
LM – Voi utilizzate Toradex come piattaforma hardware, che supporta diversi sistemi operativi. Quale sistema avete scelto?
TL – Finora abbiamo sempre avuto una buona collaborazione con Toradex, usando il loro Apalis i.MX6 SoM. Quindi per la prossima generazione di infotainment di Rimac Automobili la nostra idea è di passare al nuovo e più potente Apalis i.MX8 SoM. Utilizziamo una distro Linux embedded personalizzata, basata su Yocto. Dal momento che sviluppiamo un sacco di hardware personalizzato, e abbiamo dei requisiti molto particolari, la natura open source di Linux ci fornisce la libertà e il controllo sul prodotto finale di cui abbiamo bisogno.
LM – Rimac realizza le proprie interfacce anche per altri produttori di automobili. Come progettare il vostro hardware/software?
TL – In Rimac Automobili vediamo i nostri veicoli come il nostro brand e un modo per presentare la nostra tecnologia. Tutta la tecnologia che inseriamo nelle nostre auto rappresenta il fiore all’occhiello di quello che possiamo offrire agli altri. Questo si riflette nella filosofia con cui progettiamo il nostro hardware e software. Siccome puntiamo a un mercato di lusso e di nicchia, il numero limitato di esemplari prodotti per ogni serie ci spinge a progettare dell’hardware altamente adattabile e un software modulare. L’hardware è progettato per supportare un ampia gamma delle ultime tecnologie disponibili, permettendoci di adattarlo rapidamente alle specifiche richieste dei nostri clienti. Allo stesso modo, il nostro software è progettato con un approccio basato sui microservizi e un sistema distribuito, il che ci permette di portare rapidamente le funzionalità da un progetto all’altro e avere sistemi che possono supportare un qualsiasi numero di schermi gestiti da un qualsiasi numero di unità computazionali.
LM – La Rimac C_Two sarà la prima automobile con una guida autonoma di livello 4. Dal momento che l’auto può raggiungere velocità notevoli, avrete bisogno di molti sensori e computer con bassa latenza. Quali sensori utilizzate?
TL – Anche se la guida autonoma è gestita da un altro team di sviluppatori, farò del mio meglio per rispondere. L’auto è equipaggiata con sensori a ultrasuoni, diversi radar, un lidar, e un totale di 8 videocamere per monitorare ci che la circonda. Ci sono altri sensori come unità di misura inerziali, sistemi di rilevamento del guidatore, eccetera. Sono usati per diverse cose, dal rilevamento della pioggia alla verifica del fatto che il guidatore sia sveglio e cosciente, mappatura di ciò che circonda l’auto, evitare le collisioni, e molto altro. È difficile dare una idea della potenza di calcolo della C Two, ma diciamo che se si programmasse la macchina per minare criptovalute l’auto si ripagherebbe da sola piuttosto velocemente.
LM – È vero che un’ora di guida sulla Rimac C Two produce circa 6TeraByte di dati? Come fate a gestire tutte queste informazioni senza stalli?
TL – A seconda della modalità di guida, la quantità di dati processata dal sistema può essere anche superiore ai 6TB per ogni ora. La maggioranza delle unità computazionali è connessa tramite la rete CAN, che gestisce la maggior parte del traffico dati dipendente dal tempo, che è relativamente ridotto in termini di volume. La parte che genera più dati è rappresentata dalle mappe dell’ambiente circostante del sistema ADAS, che includono video HD, modelli 3D della strada, e centinaia di segnali con una risoluzione di un millisecondo, che devono essere rilevati sia per l’ADAS che per l’algoritmo di gestione della coppia, e per la scatola nera del veicolo. Inoltre, catturiamo diverse centinaia di segnali con diverse risoluzioni per il nostro sistema di telemetria, che ci permette di monitorare la salute del veicolo in ogni momento. L’ammontare totale dei dati prodotti dall’automobile dipendono dal fatto che si stia usando la guida autonoma o no, da come è configurata la telemetria, e quali dati il proprietario decide di registrare.
LM – La Rimac C_Two ha un sistema di riconoscimento facciale che sostituisce la chiave di avviamento. Al momento molte persone non sono convinte dal fatto di essere riprese da una videocamera se non sanno come funzioni esattamente il sistema. È una situazione in cui l’open source può risultare utile: se il codice è liberamente disponibile i clienti potranno sapere che le immagini non verranno usate senza il loro permesso. A suo parere, può essere possibile in futuro rilasciare il codice di alcuni sistemi dell’auto, per guadagnare la fiducia dei clienti?
TL – Questo è un problema complicato, che deve essere esaminato sotto diversi punti di vista. Nonostante io personalmente sia convinto che rendere alcuni sistemi open source aumenterebbe la fiducia del cliente, potrebbe anche rendere più facile per i malintenzionati la progettazione di attacchi contro il sistema stesso. Inoltre, da un lato l’open source aiuta a costruire una community che utilizza attivamente la tecnologia, la migliora e corregge gli errori. Ma allo stesso tempo è diametralmente opposto al mantenere la proprietà intellettuale del prodotto. La mia opinione è che in Rimac Automobili dovremmo provare questa opzione.
LM – Più in generale, quale dovrebbe essere il corretto equilibrio tra open source e segreti industriali?
TL – Personalmente, credo che il bilancio dovrebbe puntare all’open source più di quanto molte persone potrebbero pensare. Molti sistemi potrebbero essere rilasciati come open source senza alcun danno per l’azienda. Solo un gruppo molto ristretto di informazioni dovrebbe rimanere un segreto brevettato. Credo che oggi come oggi sia molto più importante fare una cosa bene, avere un buon rapporto con le aziende partner e un buon prodotto, piuttosto che provare a avere una monopolio su qualcosa. Prima o poi, qualcuno farà il reverse engineering delle tecnologie. È meglio porre gli sforzi nel produrre nuova tecnologia piuttosto che nel tenere nascosto per sempre quello che si è già fatto.

LM – Gli appassionati di automobili amano fare il car tuning, sostituire i motori, gli scarichi, eccetera. Con le auto elettriche e ad alta automazione c’è il potenziale anche per personalizzazioni a livello software. C’è la possibilità che rilasciate un SDK per permettere ad altri di sviluppare applicazioni per le vostre auto, oppure ritiene che potrebbe essere pericoloso?
TL – Vedo già apparire rari esempi di queste personalizzazioni. C’è una serie di strumenti, come FORScan, che permettono di collegare la propria macchina al computer con un adattatore USB-OBDII e modificare una serie di parametri. Un mio collega ha una automobile che permette un certo grado di personalizzazione dell’interfaccia grafica degli schermi usando uno strumento per PC. C’è un certo numero di appassionati che comprano una automobile proprio perché offre questo tipo di caratteristica. Un dettaglio interessante è che su quella specifica auto il produttore ha disabilitato questa funzione con un aggiornamento del software, quindi gli appassionati si rifiutano di fare quell’aggiornamento, e hanno trovato modi per fare il roll back dell’aggiornamento in modo da mantenere quella funzionalità. Credo che questa cosa succederà ovunque in un prossimo futuro. Però ci deve essere una qualche forma di restrizione. Permettere agli appassionati di modificare il layout dei loro schermi o la struttura dei menù degli schermi centrali è una cosa buona, visto che nella peggiore delle ipotesi ci si ritroverebbe con una interfaccia grafica brutta. Ma permettere l’accesso software alle unità computazionali, come la centralina ABS o gli airbag, è estremamente pericoloso, e credo che il rischio per la vita umana, così come la responsabilità legale, sia semplicemente troppo grande per consentire questo tipo di modifiche.
LM – Ovviamente, una automobile altamente automatizzata può essere vittima di pirateria informatica, è già successo a altri produttori di auto. Come avete protetto i computer della Rimac C_Two dai potenziali attacchi?
TL – Stiamo attivamente proteggendo la C_Two con più livelli di protezione possibili. Non possiamo pensare di proteggerci con uno strumento solo: ogni livello deve proteggere la macchina da uno specifico tipo di attacco. A basso livello cose come la numerazione della sequenza dei messaggi CAN e la loro checksum proteggono dall’iniezione di messaggi non validi. Sul livello dell’infotainment, cose come la crittografia delle partizioni e la firma digitale dell’intera immagine del sistema operativo proteggono dall’avvio di un sistema operativo compromesso. La macchina di per se non ha servizi che possano accettare connessioni da internet, è sempre la macchina a connettersi a un server. Utilizziamo gli ultimi algoritmi di crittografia e dei messaggi di autorizzazione per garantire l’identità dell’automobile e del server. Il server che ospita il sistema M2M presenta le sue sfide, simili alle sfide di una banca per proteggere i dati dei suoi clienti. In Rimac Automobili vediamo questa cosa come uno sforzo congiunto di diversi team di progettisti e, come in tutti i problemi di cybersecurity, rimarrà sempre una gara tra noi e i pirati informatici.