Sembrano immagini da un universo parallelo, ma le immagini mostrate in questo filmato del 1968 (YouTube) sono la realtà di quello che già si faceva nei laboratori della Bell alla fine degli anni Sessanta: grafica digitale, composizione di musica al computer, progettazione virtuale di circuiti elettronici usando uno stilo (o penna ottica come si chiamava all’epoca), simulazioni 3D di orbite spaziali, sintesi vocale, concezione di film generati al computer, e altro ancora. I macchinari di allora erano enormi, lentissimi e costosissimi: oggi abbiamo a disposizione le stesse risorse sui nostri telefonini.
A 10:00 una chicca per gli appassionati di fantascienza: la scena che quasi sicuramente ispirò Stanley Kubrick per la famosa sequenza di 2001: Odissea nello spazio nella quale il computer intelligente HAL (spoiler!) subisce una lobotomia e gli viene chiesto di cantare una canzoncina per segnalare il progressivo degrado delle sue capacità intellettive. La canzoncina, in questo documentario e nel film, è Daisy Bell; nell’edizione italiana venne sostituita con la filastrocca Giro Girotondo. Si perse così il riferimento a queste sperimentazioni della Bell e anche una battuta sottile nel testo della canzoncina, quando HAL dice “I’m half crazy” (sono mezzo matto).
Il documentario si intitola The Incredible Machine ed è datato 1968. I sottotitoli automatici di YouTube sono pieni di errori; non fidatevi di quello che scrivono.
Qui trovate il programma in Perl per far cantare Daisy Bell alla sintesi vocale del Mac.
Secondo la didascalia del video su YouTube, si tratta del sistema informatico Graphic 1 dei Bell Labs, composto da un PDP-5 della Digital Equipment Corporation accoppiato a periferiche come una penna ottica Type 370, una tastiera da telescrivente Teletype Model 33 della Teletype Corporation, e un display incrementale di precisione DEC Type 340 coadiuvato da una memoria buffer RVQ della Ampex capace di immagazzinare 4096 parole (words). La risoluzione sul monitor era 1024×1024 (una foto su Instagram di oggi, per capirci). Ripeto, siamo nel 1968 e questi avevano già monitor con queste caratteristiche. L’output grafico veniva passato a un sistema IBM 7094 da 200 kflop/secondo, collegato a un registratore su microfilm SC 4020 della Stromberg Carlson che, sempre stando alla didascalia, “ci metteva ore a leggere e registrare i dati”. Ma le avvisaglie di tutto quello che conosciamo oggi c’erano già.
Venerdì 22 novembre alle 17.30, presso il Centro Esposizioni Lugano, sarò moderatore di una tavola rotonda intitolata Le nuove tecnologie digitali applicate alla progettazione/costruzione: la nuova era dell’intelligenza artificiale e la robotica nell’edilizia, nell’ambito del Salone dell’Edilizia Edilespo.
Per un’ora e un quarto avrò il piacere di moderare esperti d’eccezione e di parlare anche di Robodog, un cane-robot guida per ciechi. Questi sono i partecipanti alla tavola rotonda:
Professor Andrea Emilio Rizzoli, direttore dell’Istituto Dalle Molle di studi sull’intelligenza artificiale USI-SUPSI
Architetto Loris Dellea, direttore della CAT (Conferenza delle Associazioni Tecniche del Cantone Ticino)
Davide Plozza, ricercatore del politecnico di Zurigo e sviluppatore di Robodog
Alessandro Marrarosa, rappresentante di Digitalswitzerland
Christian Righinetti, esperto UAS (Unmanned Aircraft Systems) di DroneAir
A seguire ci sarà un aperitivo offerto da Securiton SA – Taverne e CAT (Conferenza delle Associazioni Tecniche del Cantone Ticino).
Questo è il testo della puntata del 25 novembre 2024 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
[CLIP: brano della versione italiana della sigla iniziale della serie TV Il Prigioniero]
Sta circolando un’accusa pesante che riguarda il popolarissimo software Word di Microsoft: userebbe i testi scritti dagli utenti per addestrare l’intelligenza artificiale dell’azienda. Se l’accusa fosse confermata, le implicazioni in termini di privacy, confidenzialità e diritto d’autore sarebbero estremamente serie.
Questa è la storia di quest’accusa, dei dati che fin qui la avvalorano, e di come eventualmente rimediare. Benvenuti alla puntata del 25 novembre 2024 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Le intelligenze artificiali hanno bisogno di dati sui quali addestrarsi. Tanti, tanti dati: più ne hanno, più diventano capaci di fornire risposte utili. Un’intelligenza artificiale che elabora testi, per esempio, deve acquisire non miliardi, ma migliaia di miliardi di parole per funzionare decentemente.
Procurarsi così tanto testo non è facile, e quindi le aziende che sviluppano intelligenze artificiali pescano dove possono: non solo libri digitalizzati ma anche pagine Web, articoli di Wikipedia, post sui social network. E ancora non basta. Secondo le indagini del New York Times [link diretto con paywall; copia su Archive.is], OpenAI, l’azienda che sviluppa ChatGPT, aveva già esaurito nel 2021 ogni fonte di testo in inglese pubblicamente disponibile su Internet.
Per sfamare l’appetito incontenibile della sua intelligenza artificiale, OpenAI ha creato uno strumento di riconoscimento vocale, chiamato Whisper, che trascriveva il parlato dei video di YouTube e quindi produceva nuovi testi sui quali continuare ad addestrare ChatGPT. Whisper ha trascritto oltre un milione di ore di video di YouTube, e dall’addestramento basato su quei testi è nato ChatGPT 4.
Questa stessa trascrizione di massa l’ha fatta anche Google, che inoltre ha cambiato le proprie condizioni di servizio per poter acquisire anche i contenuti dei documenti pubblici scritti su Google Docs, le recensioni dei ristoranti di Google Maps, e altro ancora [New York Times].
Da parte sua, Meta ha avvisato noi utenti che da giugno di quest’anno usa tutto quello che scriviamo pubblicamente su Facebook e Instagram per l’addestramento delle sue intelligenze artificiali, a meno che ciascuno di noi non presenti formale opposizione, come ho raccontato nella puntata del 7 giugno 2024.
Insomma, la fame di dati delle intelligenze artificiali non si placa, e le grandi aziende del settore sono disposte a compromessi legalmente discutibili pur di poter mettere le mani sui dati che servono. Per esempio, la legalità di usare massicciamente i contenuti creati dagli YouTuber senza alcun compenso o riconoscimento è perlomeno controversa. Microsoft e OpenAI sono state portate in tribunale negli Stati Uniti con l’accusa di aver addestrato il loro strumento di intelligenza artificiale Copilot usando milioni di righe di codice di programmazione pubblicate sulla piattaforma GitHub senza il consenso dei creatori di quelle righe di codice e violando la licenza open source adottata da quei creatori [Vice.com].
In parole povere, il boom dell’intelligenza artificiale che stiamo vivendo, e i profitti stratosferici di alcune aziende del settore, si basano in gran parte su un saccheggio senza precedenti della fatica di qualcun altro. E quel qualcun altro, spesso, siamo noi.
In questo scenario è arrivata un’accusa molto specifica che, se confermata, rischia di toccarci molto da vicino. L’accusa è che se scriviamo un testo usando Word di Microsoft, quel testo può essere letto e usato per addestrare le intelligenze artificiali dell’azienda.
Questo vorrebbe dire che qualunque lettera confidenziale, referto medico, articolo di giornale, documentazione aziendale riservata, pubblicazione scientifica sotto embargo sarebbe a rischio di essere ingerita nel ventre senza fondo delle IA, dal quale si è già visto che può essere poi rigurgitata, per errore o per dolo, rendendo pubblici i nostri dati riservati, tant’è vero che il già citato New York Times è in causa con OpenAI e con Microsoft perché nei testi generati da ChatGPT e da Copilot compaiono interi blocchi di testi di articoli della testata, ricopiati pari pari [Harvard Law Review].
Vediamo su cosa si basa quest’accusa.
Il 13 novembre scorso il sito Ilona-andrews.com, gestito da una coppia di scrittori, ha segnalato un problema con la funzione Esperienze connesse di Microsoft Word [Connected Experiences nella versione inglese]. Se non avete mai sentito parlare di questa funzione, siete in ottima e ampia compagnia: è sepolta in una parte poco frequentata della fitta foresta di menu e sottomenu di Word. Nell’articolo che accompagna questo podcast sul sito Attivissimo.me trovate il percorso dettagliato da seguire per trovarla, per Windows e per Mac.
Word per Windows (applicazione): File – Opzioni – Centro protezione – Impostazioni Centro protezione – Opzioni della privacy – Impostazioni di privacy – Dati di diagnostica facoltativi [in inglese: File – Options – Trust Center – Trust Center Settings – Privacy Options – Privacy Settings – Optional Connected Experiences]
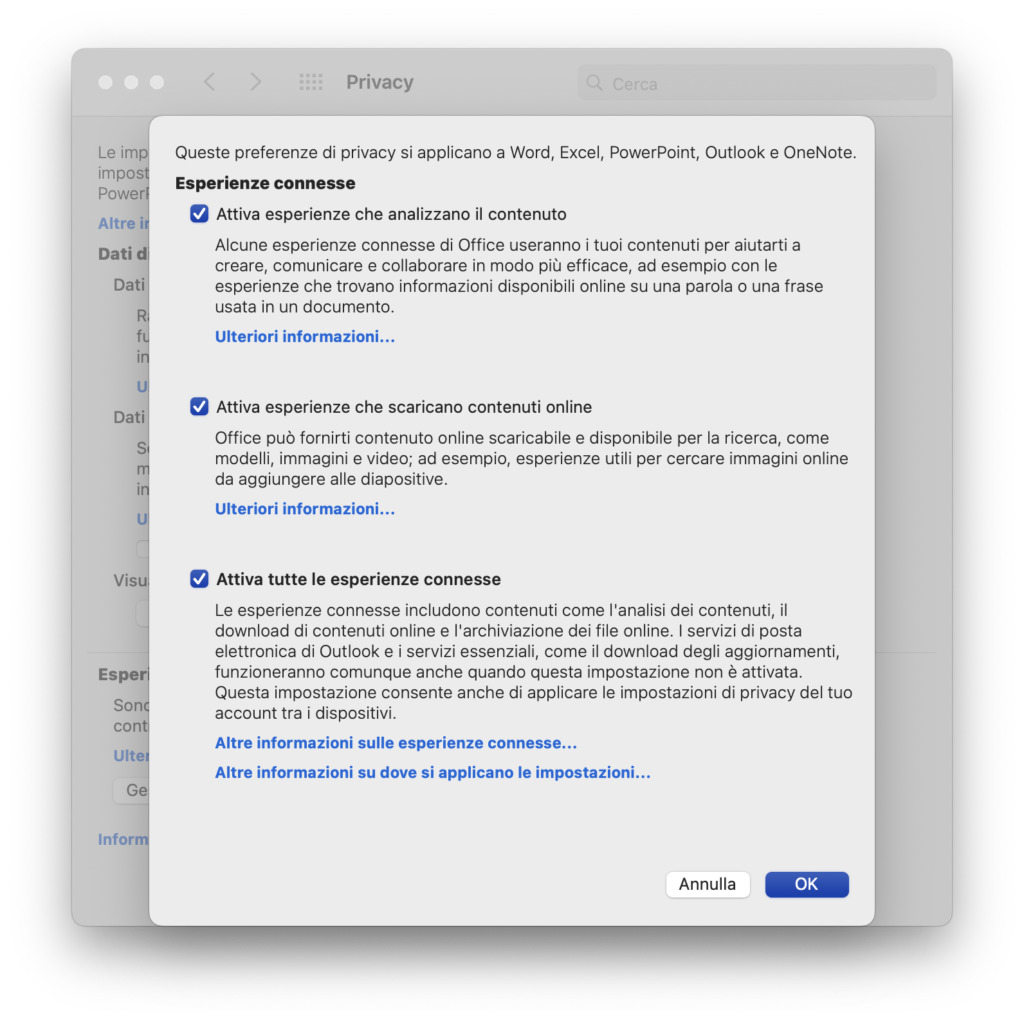
Word per Mac (applicazione): Word – Preferenze – Privacy – Gestisci le esperienze connesse [in inglese: Word – Preferences – Privacy – Manage Connected Experiences]
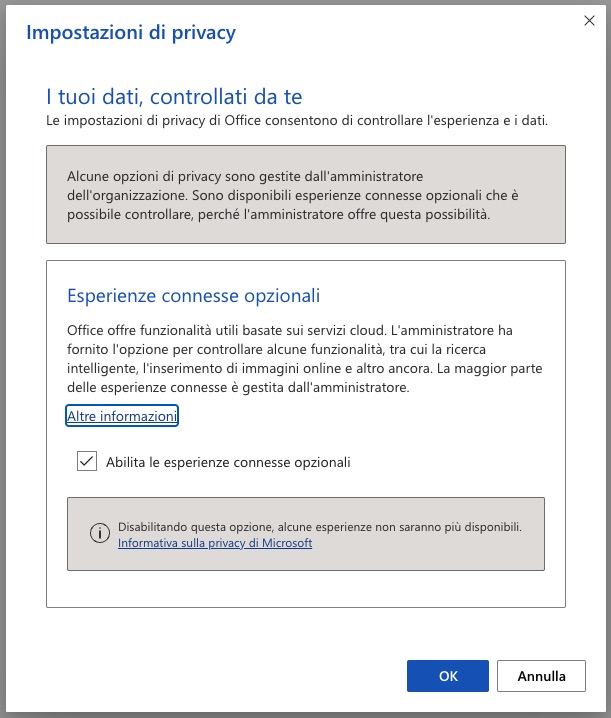
Word su Web: File – Informazioni – Impostazioni privacy
Screenshot da Word per Mac italiano.
Screenshot da Word su web in italiano.
Secondo questa segnalazione di Ilona-andrews.com, ripresa e approfondita anche da Casey Lawrence su Medium.com, Microsoft avrebbe attivato senza troppo clamore in Office questa funzione, che leggerebbe i documenti degli utenti allo scopo di addestrare le sue intelligenze artificiali. Questa funzione è di tipo opt-out, ossia viene attivata automaticamente a meno che l’utente richieda esplicitamente la sua disattivazione.
L’informativa sulla privacy di Microsoft collegata a questa funzione dice testualmente che i dati personali raccolti da Microsoft vengono utilizzati, fra le altre cose, anche per “Pubblicizzare e comunicare offerte all’utente, tra cui inviare comunicazioni promozionali, materiale pubblicitario mirato e presentazioni di offerte pertinenti.” Traduzione: ti bombarderemo di pubblicità sulla base delle cose che scrivi usando Word. E già questo, che è un dato di fatto dichiarato da Microsoft, non è particolarmente gradevole.
Ma c’è anche un altro passaggio dell’informativa sulla privacy di Microsoft che è molto significativo: “Nell’ambito del nostro impegno per migliorare e sviluppare i nostri prodotti” dice “Microsoft può usare i dati dell’utente per sviluppare ed eseguire il training dei modelli di intelligenza artificiale”.
Sembra abbastanza inequivocabile, ma bisogna capire cosa intende Microsoft con l’espressione “dati dell’utente”. Se include i documenti scritti con Word, allora l’accusa è concreta; se invece non li include, ma comprende per esempio le conversazioni fatte con Copilot, allora il problema c’è lo stesso ed è serio ma non così catastroficamente grave come può parere a prima vista.
Secondo un’altra pagina informativa di Microsoft, l’azienda dichiara esplicitamente di usare le “conversazioni testuali e a voce fatte con Copilot”*, con alcune eccezioni: sono esclusi per esempio gli utenti autenticati che hanno meno di 18 anni, i clienti commerciali di Microsoft, e gli utenti europei (Svizzera e Regno Unito compresi).**
* “Except for certain categories of users (see below) or users who have opted out, Microsoft uses data from Bing, MSN, Copilot, and interactions with ads on Microsoft for AI training. This includes anonymous search and news data, interactions with ads, and your voice and text conversations with Copilot [...]”
** “Users in certain countries including: Austria, Belgium, Brazil, Bulgaria, Canada, China, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Israel, Italy, Latvia, Liechtenstein, Lithuania, Luxembourg, Malta, the Netherlands, Norway, Nigeria, Poland, Portugal, Romania, Slovakia, Slovenia, South Korea, Spain, Sweden, Switzerland, the United Kingdom, and Vietnam. This includes the regions of Guadeloupe, French Guiana, Martinique, Mayotte, Reunion Island, Saint-Martin, Azores, Madeira, and the Canary Islands.”
Nella stessa pagina, Microsoft dichiara inoltre che non addestra i propri modelli di intelligenza artificiale sui dati personali presenti nei profili degli account Microsoft o sul contenuto delle mail, e aggiunge che se le conversazioni fatte con l’intelligenza artificiale dell’azienda includono delle immagini, Microsoft rimuove i metadati e gli altri dati personali e sfuoca i volti delle persone raffigurate in quelle immagini. Inoltre rimuove anche i dati che potrebbero rendere identificabile l’utente, come nomi, numeri di telefono, identificativi di dispositivi o account, indirizzi postali e indirizzi di mail, prima di addestrare le proprie intelligenze artificiali.
Secondo le indagini di Medium.com, inoltre, le Esperienze connesse sono attivate per impostazione predefinitaper gli utenti privati, mentre sono automaticamente disattivate per gli utenti delle aziende che usano la crittografia DKE per proteggere file e mail.
In sintesi, la tesi che Microsoft si legga i documenti Word scritti da noi non è confermata per ora da prove concrete, ma di certo l’azienda ammette di usare le interazioni con la sua intelligenza artificiale a scopo pubblicitario, e già questo è piuttosto irritante. Scoprire come si fa per disattivare questo comportamento e a chi si applica è sicuramente un bonus piacevole e un risultato utile di questo allarme.
Ma visto che gli errori possono capitare, visto che i dati teoricamente anonimizzati si possono a volte deanonimizzare, e visto che le aziende spesso cambiano le proprie condizioni d’uso molto discretamente, è comunque opportuno valutare se queste Esperienze connesse vi servono davvero ed è prudente disattivarle se non avete motivo di usarle, naturalmente dopo aver sentito gli addetti ai servizi informatici se lavorate in un’organizzazione. Le istruzioni dettagliate, anche in questo caso, sono su Attivissimo.me.
E se proprio non vi fidate delle dichiarazioni delle aziende e volete stare lontani da questa febbre universale che spinge a infilare dappertutto l’intelligenza artificiale e la raccolta di dati personali, ci sono sempre prodotti alternativi a Word ed Excel, come LibreOffice, che non raccolgono assolutamente nulla e non vogliono avere niente a che fare con l’intelligenza artificiale.
Il problema di fondo, però, rimane: le grandi aziende hanno una disperata fame di dati per le loro intelligenze artificiali, e quindi continueranno a fare di tutto per acquisirli. Ad aprile 2023 Meta, che possiede Facebook, Instagram e WhatsApp, ha addirittura valutato seriamente l’idea di comperare in blocco la grande casa editrice statunitense Simon & Schuster pur di poter accedere ai contenuti testuali di alta qualità costituiti dal suo immenso catalogo di libri sui quali ha i diritti [New York Times].
OpenAI, invece, sta valutando un’altra soluzione: addestrare le intelligenze artificiali usando contenuti generati da altre intelligenze artificiali. In altre parole, su dati sintetici. Poi non sorprendiamoci se queste tecnologie restituiscono spesso dei risultati che non c’entrano nulla con la realtà. Utente avvisato, mezzo salvato.
L’attuale IA fallisce in molti compiti, ma nel riconoscimento delle immagini se la cava egregiamente. Perché non usarla per rendere Internet più accessibile a tutti, per esempio facendole scrivere automaticamente le descrizioni delle immagini sui social network?
Su Mastodon c’è @altbot@fuzzies.wtf, un bot che fa esattamente questo. È sufficiente seguirlo: fatto questo, se pubblicate un post con un’immagine per la quale non avete già scritto voi un testo alternativo per ipo e non vedenti, il bot passa l’immagine all’IA Gemini, che restituisce in una manciata di secondi una descrizione dell’immagine, che potete includere nel post editandolo.
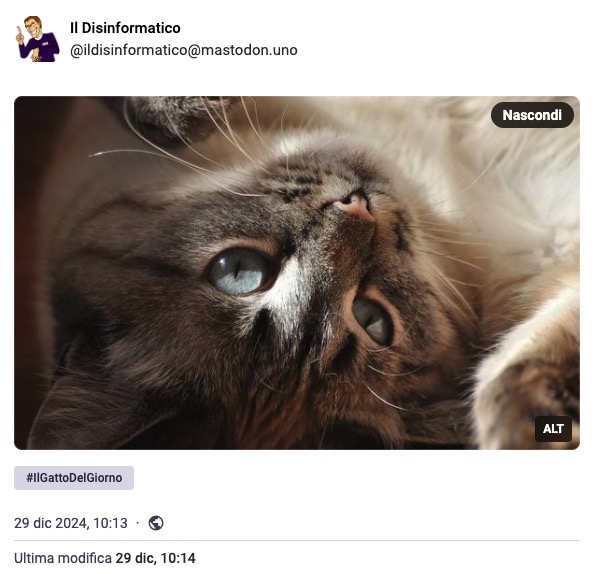
Per esempio, stamattina ho postato il consueto Gatto Del Giorno anche su Mastodon, come al solito:
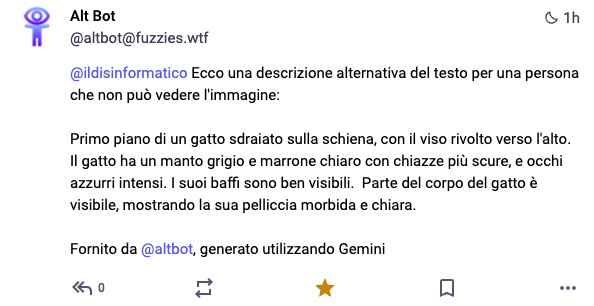
Non ho scritto intenzionalmente un testo ALT, e Altbot ha risposto così in una manciata di secondi:
@ildisinformatico Ecco una descrizione alternativa del testo per una persona che non può vedere l’immagine:
Primo piano di un gatto sdraiato sulla schiena, con il viso rivolto verso l’alto. Il gatto ha un manto grigio e marrone chiaro con chiazze più scure, e occhi azzurri intensi. I suoi baffi sono ben visibili. Parte del corpo del gatto è visibile, mostrando la sua pelliccia morbida e chiara.
È stupendamente ironico che oggi non avere integrata l’intelligenza artificiale in un prodotto sia diventato un bonus. Non stupisce che sia così, dopo tutti i disastri, le violazioni della riservatezza e le figuracce prodotte da chi si affida incautamente all’IA o se la trova imposta dagli aggiornamenti dei prodotti che usa.
Non solo: visto che tutte le principali aziende statunitensi del software hanno deciso di prostituirsi con l’amministrazione Trump e i suoi deliri imperialisti, sganciarsi il più possibile dalla dipendenza dal software prodotto da queste aziende è oggi una considerazione strategica di sopravvivenza e sovranità per privati, società e governi; non più un astratto principio culturale.
Riporto quindi con particolare piacere qui sotto l’annuncio da parte della Document Foundation della nuova versione della suite per ufficio LibreOffice, che genera documenti in formato standard ISO (leggibili quindi senza dover per forza usare lo specifico software di una specifica azienda), è gratuito (sostenuto dalle donazioni), è libero, è open source, non ha complicazioni di licenze che scadono ed è multipiattaforma. Uso da molti anni LibreOffice per quasi tutto quello che scrivo, compresi i libri.
L’annuncio riassume le novità introdotte da questa versione e fornisce i link per scaricarla e per leggere le note dettagliate di rilascio.
LibreOffice 25.2, la suite per ufficio per le esigenze degli utenti di oggi
La nuova major release offre un gran numero di miglioramenti all’interfaccia utente e all’accessibilità, oltre alle consuete funzionalità di interoperabilità
Berlino, 6 febbraio 2025 – LibreOffice 25.2, la nuova major release della suite per ufficio gratuita e supportata dalla community di volontari per Windows (Intel, AMD e ARM), macOS (Apple Silicon e Intel) e Linux è disponibile su https://www.libreoffice.org/download. LibreOffice è la migliore suite per ufficio per gli utenti che vogliono mantenere il controllo sul proprio software e sui propri documenti, proteggendo la propria privacy e la propria vita digitale dalle interferenze commerciali e dalle strategie di lock-in delle Big Tech.
LibreOffice è l’unica suite per ufficio progettata per soddisfare le esigenze reali degli utenti, e non solo la loro percezione visiva. Offre una serie di opzioni di interfaccia per adattarsi alle diverse abitudini degli utenti, da quelle tradizionali a quelle moderne, e sfrutta al meglio le diverse dimensioni degli schermi, ottimizzando lo spazio disponibile per mettere il massimo numero di funzioni a uno o due clic di distanza. È anche l’unico software per la creazione di documenti (che possono contenere informazioni personali o riservate) che rispetta la privacy dell’utente, garantendogli la possibilità di decidere se e con chi condividere i contenuti creati, grazie al formato standard e aperto che non viene utilizzato come strumento di lock-in, obbligando ad aggiornamenti periodici del software. Il tutto con un set di funzionalità paragonabile a quello dei principali software presenti sul mercato e di gran lunga superiore a quello di qualsiasi concorrente.
Ciò che rende LibreOffice unico è la piattaforma tecnologica LibreOffice, l’unica sul mercato che consente lo sviluppo coerente di versioni desktop, mobile e cloud – comprese quelle fornite dalle aziende dell’ecosistema – in grado di produrre documenti identici e completamente interoperabili basati sui due standard ISO disponibili: l’aperto ODF o Open Document Format (ODT, ODS e ODP) e il proprietario Microsoft OOXML (DOCX, XLSX e PPTX). Quest’ultimo nasconde agli utenti un gran numero di complessità artificiali (e inutili) che creano problemi a chi è convinto di utilizzare un formato standard.
Gli utenti finali possono ottenere un supporto tecnico di primo livello dai volontari attraverso sia la mailing list degli utenti sia il sito web Ask LibreOffice: https://ask.libreoffice.org.
Nuove caratteristiche di LibreOffice 25.2
PRIVACY • LibreOffice è in grado di rimuovere tutte le informazioni personali associate a qualsiasi documento (nome dell’autore e timestamp, ora di modifica, nome e configurazione della stampante, modello di documento, autore e data per i commenti e le modifiche tracciate).
CORE/GENERALE • LibreOffice 25.2 può leggere e scrivere file ODF versione 1.4. • Molti miglioramenti nell’interoperabilità con i documenti OOXML proprietari. • È ora possibile firmare automaticamente i documenti dopo aver definito un certificato predefinito. • Windows 7 e 8/8.1 sono piattaforme deprecate, e il loro supporto verrà definitivamente rimosso con la versione 25.8. • Le estensioni e le funzioni che si basano su Python non funzionano su Windows 7.
WRITER • Miglioramento della gestione del tracciamento delle modifiche, per gestire un gran numero di modifiche nei documenti più lunghi. • I commenti vengono ora tracciati nel Navigatore quando si sposta il focus su di loro, mentre il ridimensionamento dell’area contenente i commenti ora mostra una guida visuale. • Sono state aggiunte opzioni per impostare un livello di zoom predefinito per l’apertura dei documenti, sovrascrivendo il livello memorizzato nei documenti stessi. • È ora possibile eliminare tutti i contenuti dello stesso tipo (con l’esclusione delle intestazioni) tramite il Navigatore.
CALC • Aggiunta di una finestra di dialogo “Gestione dei record duplicati” per selezionare/eliminare i record duplicati. • Sia la finestra di dialogo della procedura guidata per le funzioni che l’area nella barra laterale delle funzioni sono stati migliorati per quanto riguarda la ricerca e l’esperienza dell’utente. • I modelli di Solver possono essere salvati nei fogli di calcolo, e Solver è in grado di fornire una relazione sull’analisi di sensibilità. • Aggiunta di nuove opzioni di protezione del foglio relative alle tabelle Pivot, ai grafici Pivot e ai filtri automatici.
IMPRESS E DRAW • Molti miglioramenti a tutti i modelli di Impress, che ora hanno elementi visibili (colore del carattere impostato su nero) nelle Note e negli Handout. • Gli oggetti possono essere centrati sulla diapositiva di Impress (o sulla pagina di Draw) in un unico passaggio. • La ripetizione automatica delle diapositive può ora essere attivata in modalità a finestre. • Il testo in eccesso nelle note del presentatore non viene più tagliato durante la stampa.
INTERFACCIA UTENTE • L’elenco dei file utilizzati di recente ha ora una casella di controllo “[x] Solo il modulo corrente” che consente di filtrare l’elenco. • I margini degli oggetti sono ora attivati indipendentemente dai Segni di Formattazione. • Il colore dei caratteri non stampati e il colore di sfondo dei commenti possono essere personalizzati. • Sono stati aggiornati gli elementi predefiniti per gli elenchi non ordinati (noti anche come “bullet”). • Miglioramenti significativi ai temi delle applicazioni.
ACCESSIBILITÀ • Miglioramento dei livelli di avviso e di errore nella barra laterale dell’accessibilità, con la possibilità di ignorare gli avvisi. • Gli elementi dell’interfaccia utente riportano un identificatore accessibile che può essere utilizzato dalle tecnologie assistive. • Windows: l’accessibilità viene attivata ogni volta che uno strumento richiede informazioni sul livello di accessibilità e le relazioni accessibili vengono segnalate correttamente. • Linux: le posizioni degli elementi dell’interfaccia utente (anche su Wayland) sono riportate correttamente a livello di accessibilità.
LIBRERIE DI SCRIPTFORGE • Una raccolta estensibile e robusta di risorse di macro scripting da invocare da script Basic o Python dell’utente. • L’intera serie di servizi (tranne quando la funzione incorporata nativa è migliore) è resa disponibile per gli script Python con sintassi e comportamento identici a quelli del Basic. • La documentazione in inglese delle librerie ScriptForge è ora parzialmente integrata nelle pagine di aiuto di LibreOffice.
Contributi a LibreOffice 25.2
Un totale di 176 sviluppatori ha contribuito alle nuove funzionalità di LibreOffice 25.2: il 47% dei commit di codice proviene da 50 sviluppatori impiegati da aziende dell’ecosistema – Collabora e allotropia – e da altre organizzazioni, il 31% dai sette sviluppatori di The Document Foundation e il restante 22% dai 119 singoli sviluppatori volontari.
Altri 189 volontari hanno impegnato 771.263 stringhe localizzate in 160 lingue, che rappresentano centinaia di persone che lavorano alle traduzioni. LibreOffice 25.2 è disponibile in 120 lingue, più di ogni altro software desktop, per cui può essere utilizzato da oltre 5,5 miliardi di persone nella lingua madre. Inoltre, oltre 2,4 miliardi di persone parlano una delle 120 lingue come seconda lingua.
LibreOffice per le aziende
Per le implementazioni di livello aziendale, TDF raccomanda vivamente la famiglia di applicazioni LibreOffice Enterprise dei partner dell’ecosistema – per desktop, mobile e cloud – con un’ampia gamma di funzionalità a valore aggiunto dedicate e altri vantaggi come gli SLA: https://www.libreoffice.org/download/libreoffice-in-business/.
Ogni riga di codice sviluppata dalle aziende dell’ecosistema per i clienti aziendali viene condivisa con la comunità nel repository del codice master e migliora la piattaforma LibreOffice Technology. I prodotti basati sulla tecnologia LibreOffice sono disponibili per tutti i principali sistemi operativi desktop (Windows, macOS, Linux e ChromeOS), per le piattaforme mobili (Android e iOS) e per il cloud.
Migrazioni a LibreOffice
La Document Foundation pubblica un protocollo di migrazione per aiutare le aziende a passare dalle suite per ufficio proprietarie a LibreOffice, basato sulla distribuzione di una versione LTS (supporto a lungo termine) ottimizzata per le aziende di LibreOffice, oltre alla consulenza e alla formazione per la migrazione fornite da professionisti certificati che offrono soluzioni a valore aggiunto coerenti con le offerte proprietarie. Riferimento: https://www.libreoffice.org/get-help/professional-support/.
Infatti, la maturità del codice sorgente di LibreOffice, il ricco set di funzionalità, il forte supporto agli standard aperti, l’eccellente compatibilità e le opzioni LTS di partner certificati ne fanno la soluzione ideale per le organizzazioni che vogliono riprendere il controllo dei propri dati e liberarsi dal vendor lock-in.
Per gli utenti che non hanno bisogno delle ultime funzionalità e preferiscono una versione che è stata sottoposta a un maggior numero di test e di correzioni di bug, The Document Foundation mantiene ancora la famiglia LibreOffice 24.8, che include diversi mesi di correzioni di backporting. La versione attuale è LibreOffice 24.8.4.
Gli utenti di LibreOffice, i sostenitori del software libero e i membri della comunità possono sostenere The Document Foundation con una donazione su https://www.libreoffice.org/donate.
La mia novità preferita è la possibilità di imporre un livello di zoom ignorando quello salvato nel documento: visto che ricevo e maneggio moltissimi documenti generati da terzi, che ovviamente usano un vasto assortimento di livelli di zoom del tutto inadatti al modo in cui lavoro io (monitor 4K da 120 cm di diagonale), passo parecchio tempo a ridimensionare e reinquadrare documenti. Ora li posso vedere subito con il livello di zoom perfetto (Fit Width). Quest’opzione è nelle impostazioni di LibreOffice sotto LibreOffice Writer – View – Zoom – Use preferred values.
Le tensioni tra Washington e Pechino trasformano il commercio mondiale. Mentre gli USA guidano il disaccoppiamento, l'Europa resta dipendente dalla Cina. Le aziende tech cercano alternative in Asia e Messico
Le attività di valutazione dei rischi richiedono la determinazione di criteri, metriche e logiche che non possono prescindere da una adeguata classificazione dei rischi. Comprendere come impostare le diverse tassonomie può aiutare ad evitare errori metodologici, vediamo come
Il nuovo processore Majorana 1 segna una svolta nel quantum computing usando particelle teorizzate da Ettore Majorana. L'obiettivo è integrare la potenza quantistica nei servizi cloud, rivoluzionando settori come farmaceutica e scienza dei materiali
La Cina sta rapidamente colmando il divario tecnologico con gli USA nell'intelligenza artificiale, nonostante le sanzioni. Aziende come Alibaba e DeepSeek sfidano i giganti americani con modelli open-source innovativi ed efficienti
La decisione di Meta di abbandonare il fact-checking tradizionale si scontra con il quadro normativo europeo. Tra DSA e nuove regole, le piattaforme social devono bilanciare libertà d'espressione e lotta alla disinformazione