Podcast RSI – A che punto è l’auto a guida autonoma? A San Francisco è già in strada ma non in vendita
Questo è il testo della puntata del 3 febbraio 2025 del podcast Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto. Il testo include anche i link alle fonti di questa puntata.
Le puntate del Disinformatico sono ascoltabili anche tramite iTunes, YouTube Music, Spotify e feed RSS.
[CLIP: rumori del traffico veicolare di San Francisco, registrati da me pochi giorni fa in loco]
Pochi giorni fa sono stato a San Francisco, una delle poche città al mondo nelle quali delle automobili completamente prive di conducente, guidate da speciali computer di bordo, circolano in mezzo al normale traffico veicolare e pedonale.
Sono i taxi di Waymo, un’azienda che da anni sta lavorando alla guida autonoma e da qualche tempo offre appunto un servizio commerciale di trasporto passeggeri a pagamento. I clienti usano un’app per prenotare la corsa e un’auto di Waymo li raggiunge e accosta per accoglierli a bordo, come un normale taxi, solo che al posto del conducente non c’è nessuno. Il volante c’è, ma gira da solo, e l’auto sfreccia elettricamente e fluidamente nel traffico insieme ai veicoli convenzionali. È molto riconoscibile, perché la selva di sensori che le permettono di fare tutto questo sporge molto cospicuamente dalla carrozzeria in vari punti e ricopre il tetto della vettura, formando una sorta di cappello high-tech goffo e caratteristico, e queste auto a San Francisco sono dappertutto: uno sciame silenzioso di robot su ruote che percorre incessantemente le scoscese vie della città californiana.*
* Purtroppo non sono riuscito a provare questi veicoli: l’app necessaria per prenotare un taxi di Waymo è disponibile solo per chi ha l‘App Store o Play Store statunitense e non ho avuto tempo di organizzarmi con una persona del posto che la installasse e aprisse un account.
Ma allora la sfida tecnologica della guida autonoma è risolta e dobbiamo aspettarci prossimamente “robotaxi” come questi anche da noi? Non proprio; c’è ancora letteralmente tanta strada da fare. Provo a tracciarla in questa puntata, datata 3 febbraio 2025, del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Benvenuti. Io sono Paolo Attivissimo.
[SIGLA di apertura]
È il sogno di ogni pendolare a quattro ruote: un’auto che si guida da sola, nella quale è sufficiente salire a bordo e dirle la destinazione desiderata per poi potersi rilassare completamente per tutto il viaggio, senza dover gestire code o ingorghi e senza trascorrere ore frustranti dietro il volante. Un sogno che ha radici lontane: i primi esperimenti di guida almeno parzialmente autonoma iniziarono alla fine degli anni Settanta del secolo scorso e furono svolti in Germania, Giappone e Italia [Computerhistory.org]. Ma si trattava di veicoli costosissimi, stracarichi di computer che ne riempivano il bagagliaio, e comunque funzionavano solo su strade semplici e ben demarcate. Anche così, ogni tanto dovevano arrendersi e chiedere aiuto umano.
Ma le strade di una città sono invece complesse, caotiche, piene di segnaletica da decodificare e di ostacoli che possono comparire all’improvviso e confondere i sistemi di riconoscimento automatici: per esempio un pedone che attraversa la strada, un cantiere, un’ambulanza o anche semplicemente un riflesso dell’auto stessa in una vetrata oppure una figura umana stampata sul portellone posteriore di un camion o su un cartellone pubblicitario.
Per cominciare a interpretare tutti questi fattori è stato necessario attendere a lungo che migliorasse il software e diventasse meno ingombrante l’hardware: il primo viaggio su strada urbana normale di un’automobile autonoma, senza conducente e senza scorta di polizia, risale a meno di dieci anni fa ad opera del progetto di Google per la guida autonoma, poi trasformatosi in Waymo.
Waymo è stata la prima a offrire un servizio commerciale di veicoli autonomi su strade urbane, a dicembre 2018 [Forbes], dopo dieci anni di sperimentazione, con un servizio di robotaxi limitato ad alcune zone della città statunitense di Phoenix e comunque all’epoca con un conducente d’emergenza a bordo. Nel 2021 a Shenzen, in Cina, ha debuttato il servizio di robotaxi gestito da Deeproute.ai. Nel 2022 a Waymo si è affiancata la concorrente Cruise, che è stata la prima a ottenere il permesso legale di fare a meno della persona dietro il volante, pronta a intervenire, in un servizio commerciale [CNBC].
Anche Uber aveva provato a entrare nel settore della guida autonoma, ma aveva sospeso la sperimentazione dopo che uno dei suoi veicoli di test aveva investito e ucciso un pedone, Elaine Herzberg, nel 2018 in Arizona, nonostante la presenza di un supervisore umano a bordo.
Probabilmente avete notato che fra i nomi che hanno segnato queste tappe dell’evoluzione della guida autonoma manca quello di Tesla, nonostante quest’azienda sia considerata da una buona parte dell’opinione pubblica come quella che fabbrica auto che guidano da sole. Non è affatto così: anche se il suo software si chiama Full Self-Drive, in realtà legalmente il conducente è tenuto a restare sempre pronto a intervenire.*
* Non è solo un requisito legale formale, mostrato esplicitamente sullo schermo a ogni avvio: deve proprio farlo, perché ogni tanto FSD sbaglia molto pericolosamente, anche nella versione più recente chiamata ora FSD (Supervised), come ben documentato da questa prova pratica di Teslarati di gennaio 2025.
E la famosa demo del 2016 in cui una Tesla effettuava un tragitto urbano senza interventi della persona seduta al posto di guida era una messinscena, stando a quanto è emerso in tribunale. A fine gennaio 2025 Elon Musk ha dichiarato che Tesla offrirà la guida autonoma senza supervisione a Austin, in Texas, a partire da giugno di quest’anno, a titolo sperimentale.
Ma come mai Tesla è rimasta così indietro rispetto alle concorrenti? Ci sono due motivi: uno tecnico, molto particolare, e uno operativo e poco pubblicizzato.
Ci sono fondamentalmente due approcci distinti alla guida autonoma. Uno è quello di mappare in estremo dettaglio e preventivamente le strade e consentire ai veicoli di percorrere soltanto le strade mappate in questo modo, il cosiddetto geofencing o georecinzione, dotando le auto di un assortimento di sensori di vario genere, dalle telecamere ai LiDAR, ossia sensori di distanza basati su impulsi laser.
Questo consente al veicolo [grazie al software di intelligenza artificiale che ha a bordo] di “capire” con molta precisione dove si trova, che cosa ha intorno a sé in ogni momento e di ricevere in anticipo, tramite aggiornamenti continui via Internet, segnalazioni di cantieri o di altri ostacoli che potrà incontrare.
Questa è la via scelta da Waymo e Cruise, per esempio, e funziona abbastanza bene, tanto che le auto di queste aziende sono già operative e hanno un tasso di incidenti estremamente basso, inferiore a quello di un conducente umano medio [CleanTechnica]. Ma è anche una soluzione molto costosa: richiede sensori carissimi e ingombranti e impone un aggiornamento costante della mappatura, ma soprattutto limita le auto a zone ben specifiche.
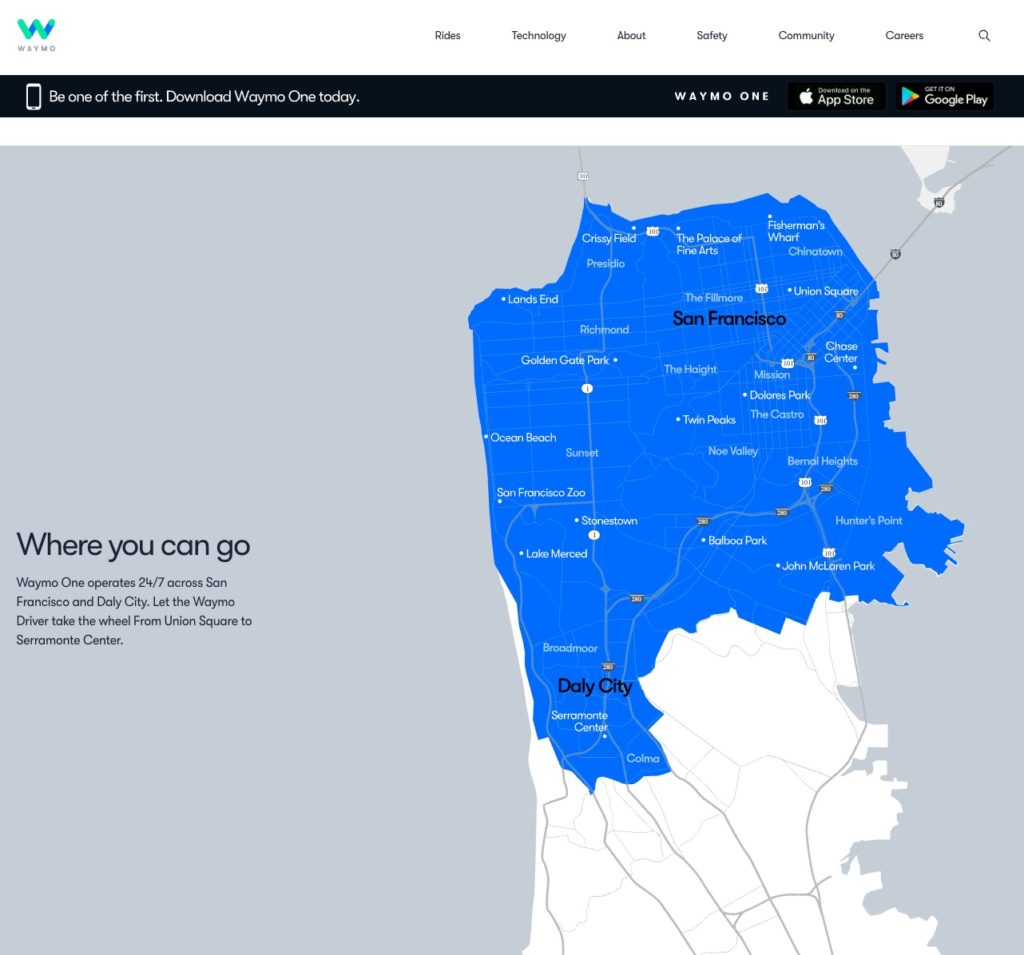
Anche a San Francisco, per esempio, Waymo è usabile soltanto in alcune parti della città [Waymo]*, e per aggiungere al servizio un’altra città bisogna prima mapparla tutta con precisione centimetrica.
Waymo sta iniziando a provare le proprie auto sulle autostrade (freeway) intorno a Phoenix oltre che in città, ma per ora trasportano solo dipendenti dell’azienda [Forbes].
L’altro approccio consiste nell’usare l’intelligenza artificiale a bordo del veicolo per decifrare i segnali che arrivano dai sensori e ricostruire da quei segnali la mappa tridimensionale di tutto quello che sta intorno all’auto. Questo evita tutto il lavoro preventivo di mappatura e quello di successivo aggiornamento e consente al veicolo di percorrere qualunque strada al mondo, senza restrizioni.
Questa è la via che Elon Musk ha deciso per Tesla, rinunciando inoltre ai sensori LIDAR per contenere i costi complessivi dei veicoli e usando soltanto le immagini provenienti dalle telecamere perimetrali per riconoscere gli oggetti e “capire” la situazione di tutti gli oggetti circostanti e come gestirla. Ma il riconoscimento fatto in questo modo non è ancora sufficientemente maturo, e questo fatto ha portato al ritardo di Tesla di vari anni rispetto alle aziende concorrenti.
Quale sia la soluzione migliore è ancora tutto da vedere. Waymo e Cruise stanno investendo cifre enormi, e nonostante le loro auto siano strapiene di sensori che costano più del veicolo stesso ogni tanto si trovano in situazioni imbarazzanti.
A ottobre 2023, un’auto di Cruise ha trascinato per alcuni metri un pedone che le era finito davanti dopo essere stato urtato da un’automobile guidata da una persona [Cruise]. A giugno 2024, un robotaxi di Waymo a Phoenix è andato a sbattere contro un palo telefonico mentre cercava di accostare per accogliere un cliente, perché il palo era piantato sul bordo della superficie stradale invece di sorgere dal marciapiedi e il software non era in grado di riconoscere un palo. Non si è fatto male nessuno e il problema è stato risolto con un aggiornamento del software, ma è un ottimo esempio del motivo per cui queste auto hanno bisogno di una mappatura preventiva incredibilmente dettagliata prima di poter circolare [CNN].
A dicembre 2024, inoltre, un cliente Waymo si è trovato intrappolato a bordo di uno dei taxi autonomi dell’azienda, che continuava a viaggiare in cerchio in un parcheggio senza portarlo a destinazione [BBC]. Ha dovuto telefonare all’assistenza clienti per farsi dire come ordinare al veicolo di interrompere questo comportamento anomalo, e a quanto pare non è l’unico del suo genere, visto che è diventato virale un video in cui un’altra auto di Waymo continua a girare ad alta velocità su una rotonda senza mai uscirne, fortunatamente senza nessun cliente a bordo [Reddit].
Gli episodi di intralcio al traffico da parte di veicoli autonomi vistosamente in preda allo smarrimento informatico sono sufficientemente frequenti da renderli impopolari fra le persone che abitano e soprattutto guidano nelle città dove operano i robotaxi [BBC].
Del resto, dover subire per tutta la notte per esempio il concerto dei clacson di un gruppo di auto Waymo parcheggiate e impazzite, come è successo a San Francisco l’estate scorsa, non suscita certo simpatie nel vicinato [TechCrunch].
Per risolvere tutti questi problemi, Waymo e Cruise ricorrono a un trucco.
Se ne parla pochissimo, ma di fatto quando un’auto autonoma di queste aziende non riesce a gestire da sola una situazione, interviene un guidatore umano remoto. In pratica in questi casi il costoso gioiello tecnologico diventa poco più di una grossa automobilina radiocomandata. Lo stesso farà anche Tesla con i suoi prossimi robotaxi, stando ai suoi annunci pubblici di ricerca di personale [Elettronauti].
È una soluzione efficace ma imbarazzante per delle aziende che puntano tutto sull’immagine di alta tecnologia, tanto che sostanzialmente non ne parlano* [BBC] e sono scarsissime le statistiche sulla frequenza di questi interventi da parte di operatori remoti: Cruise ha dichiarato che è intorno allo 0,6% del tempo di percorrenza, ma per il resto si sa ben poco.
*Uno dei pochi post pubblici di Waymo sui suoi guidatori remoti o fleet response agent spiega che l’operatore remoto non comanda direttamente il volante ma indica al software di bordo quale percorso seguire o quale azione intraprendere.
Lo 0,6% può sembrare pochissimo, ma significa che l’operatore umano interviene in media per un minuto ogni tre ore. Se un ascensore si bloccasse e avesse bisogno di un intervento manuale una volta ogni tre ore per farlo ripartire, quanti lo userebbero serenamente?
Per contro, va detto che pretendere la perfezione dalla guida autonoma è forse utopico; e sarebbe già benefico e accettabile un tasso di errore inferiore a quello dei conducenti umani. Nel 2023 in Svizzera 236 persone sono morte in incidenti della circolazione stradale e ne sono rimaste ferite in modo grave 4096. Quei 236 decessi sono la seconda cifra più alta degli ultimi cinque anni, e il numero di feriti gravi è addirittura il più alto degli ultimi dieci anni [ACS; BFU.ch]. Se la guida autonoma può ridurre questi numeri, ben venga, anche qualora non dovesse riuscire ad azzerarli.
Vedremo anche da noi scene come quelle statunitensi? Per ora sembra di no. È vero che il governo svizzero ha deciso che da marzo 2025 le automobili potranno circolare sulle autostrade nazionali usando sistemi di guida assistita (non autonoma) che consentono la gestione automatica della velocità, della frenata e dello sterzo, ma il conducente resterà appunto conducente e dovrà essere sempre pronto a riprendere il controllo quando necessario.
I singoli cantoni potranno designare alcuni percorsi specifici sui quali potranno circolare veicoli autonomi, senza conducente ma monitorati da un centro di controllo. Inoltre presso i parcheggi designati sarà consentita la guida autonoma, ma solo nel senso che l’auto potrà andare a parcheggiarsi da sola, senza conducente a bordo. Di robotaxi che circolano liberamente per le strade, per il momento, non se ne parla [Swissinfo].*
* In Italia, a Brescia, è iniziata la sperimentazione di un servizio di car sharing che usa la guida autonoma. Finora il singolo esemplare di auto autonoma, una 500 elettrica dotata di un apparato di sensori molto meno vistoso di quello di Waymo, ha percorso solo un chilometro in modalità interamente autonoma, è limitato a 30 km/h ed è monitorato sia da un supervisore a bordo, sia da una sala di controllo remota. È la prima sperimentazione su strade pubbliche aperte al traffico in Italia [Elettronauti].
Insomma, ancora per parecchi anni, se vogliamo assistere a scene imbarazzanti e pericolose che coinvolgono automobili, qui da noi dovremo affidarci al talento negativo degli esseri umani.
Fonti aggiuntive
Welcome To ‘Waymo One’ World: Google Moon Shot Begins Self-Driving Service—With Humans At The Wheel For Now, Forbes (2018)
Where to? A History of Autonomous Vehicles, Computerhistory.org (2014)
Waymo Road Trip Visiting 10+ Cities in 2025, CleanTechnica (2025)
Waymo employees can hail fully autonomous rides in Atlanta now, TechCrunch (2025)
Waymo to test its driverless system in ten new cities in 2025, Engadget (2025)
Waymo, Cruise vehicles have impeded emergency vehicle response 66 times this year: SFFD, KRON4 (2023)
How robotaxis are trying to win passengers’ trust, BBC (2024)
Bad Week for Unoccupied Waymo Cars: One Hit in Fatal Collision, One Vandalized by Mob, Slashdot (2025)
Hidden Waymo feature let researcher customize robotaxi’s display, TechCrunch (2025)
Tesla’s Autonomous Driving Strategy Stranded By Technological Divergence, CleanTechnica (2025)
Zeekr RT, the robotaxi built for Waymo, has the tiniest wipers, TechCrunch (2025)
Should Waymo Robotaxis Always Stop For Pedestrians In Crosswalks?, Slashdot (2025)